매일 소식을 전달하는 뉴스여성은 그 안에 어떻게 자리잡고 있을까
projected by 뉴미디어
매일 소식을 전달하는 뉴스여성은 그 안에 어떻게 자리잡고 있을까
projected by 뉴미디어

미국의 배우이자
미디어양성평등연구소를 운영 중인
지나 데이비스는 사람들이 무의식적으론 여성차별을 인지하고 있더라도 그들이 ‘얼마나’ 차별을 받는지는 모른다고 합니다. 이를 수치화 했을 때, 여성과 남성 모두가 놀랐다고 합니다. 다들 그 정도일줄은 몰랐다는 겁니다. 구체적인 수치를 보여주자 사람들은 양성평등을 위한 행동을 시작했다고 합니다.
그래서 지나 데이비스는 미디어의 여성 차별을 모두 수치화 하였고, 지나 데이비스가 디즈니에서 이에 대해 강연을 하고 난 뒤에 디즈니에서는 최초로 여성 2명이 주인공인, ‘겨울왕국’의 제작을 시작했습니다.
여성 차별의 수치화는 단순히 수치만으로도 사람들이 양성평등 의식을 재고하게 해주고, 양성평등을 위한 노력에 의의를 부여해줍니다. 뉴미디어는 컴퓨터공학과 학부생 4명으로 이루어진 팀입니다. 우리는 전공지식을 활용하여 사회 현상을 분석하고, 사회 현상 속의 여성 차별을 수치화 하려 합니다. 수치화하고 이를 사회에 알려, 대중의 양성평등 의식 향상에 긍정적인 영향을 끼치고자 합니다. IT의 활용은 가지각색인데요, IT지식은 특권이 아닌 책임이라고 생각합니다. 우리의 전공에 책임을 가지고, 지식을 이용해 기울어진 운동장에서 여성이 어디에 있는지 찾아 사람들에게 알리는 것이 목표입니다.
데이터 수집
2000년도 ~ 2019년도 기사
('여성, 여자, 남성, 남자'가 포함된 기사)10,724,446건
데이터 전처리
데이터 모델링
KNU 한국어 감성사전으로 제목 + 본문의 긍정, 부정, 중립 Score 측정
1차 긍부정 분류된 데이터 중 긍정 상위 Score 데이터 104,857개, 부정 상위 Score 데이터 104,857개, 중립 상위 Score 데이터 104,857개를 추출하여 ELECTRA를 fine-tuning한 Sentiment classification model 구현하여 성별 기사의 긍부정 예측
2005년도 ~ 2019년도 네이버 7개 카테고리(경제, 사회, 생활문화, 세계, 연예, 정치, IT과학) 랭킹뉴스로 ELECTRA를 fine-tuning하여 Category classification model 구현하여 성별 기사의 카테고리 예측
* ELECTRA : Pre-training Text Encoders as Discriminators Rather Than Genera (Clark et al , 2020)
sentiment model
Accuracy
99%
category model
Accuracy
88%
아래의 분석 결과에서 '여성'은 '여성, 여자'의 검색 결과를 의미하고 '남성'은 '남성, 남자'의 검색 결과를 의미합니다.
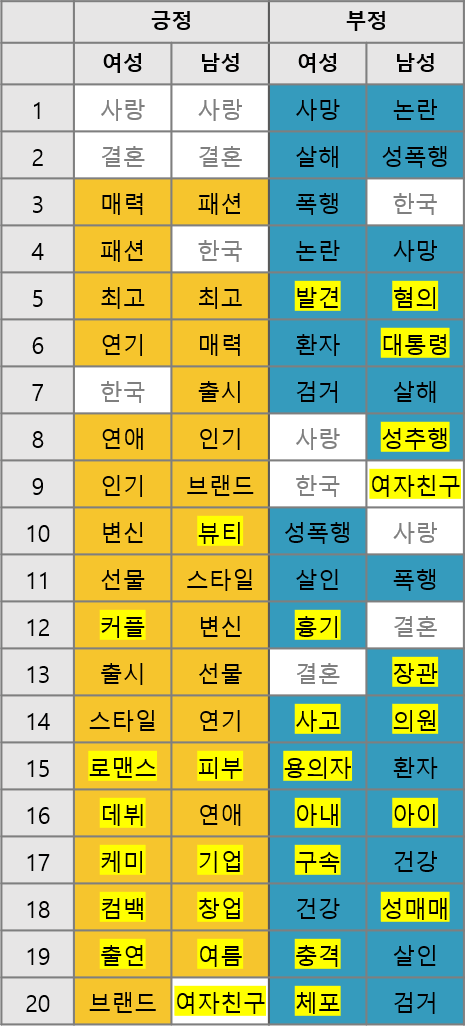
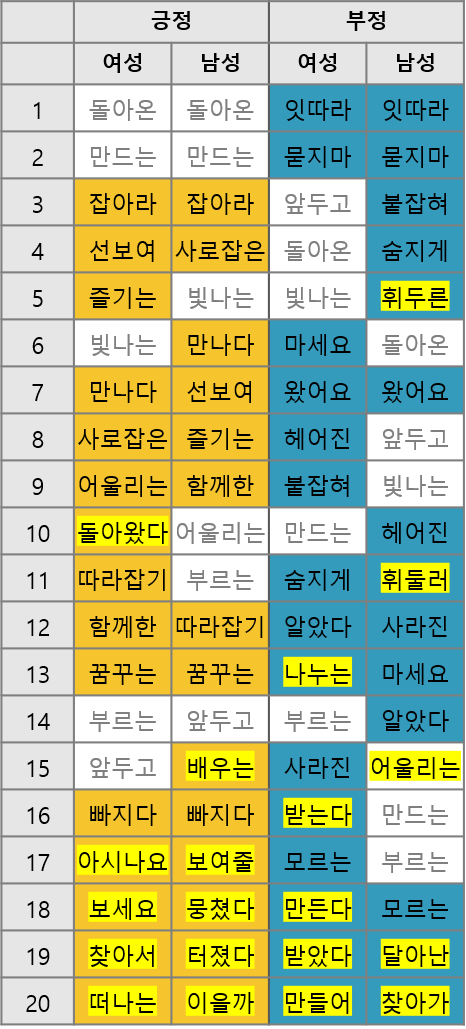
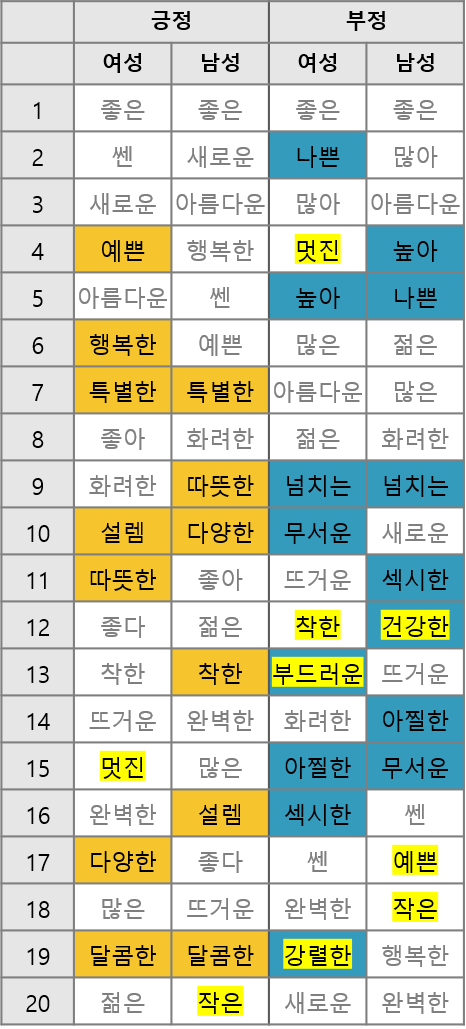
성별 기사 긍부정 비교

기사의 어느 카테고리에서 여성과 남성이 가장 많이 언급될까?
10,724,446건의 기사를 분석하여, 성별 기사의 긍부정과 카테고리별 언급 정도 및 긍부정을 수치화하고 성별 표현의 차이를 표로 정리하였습니다.
객관적 지표 전달을 목표로 했기에, 사실 발견에 초점을 두고 지난 4개월 동안 프로젝트를 진행하였습니다.
분석 결과 해석은 개인의 환경에 따라 다르리라 여겨 뉴미디어 팀의 주관적 해석을 배제하였습니다.
이 프로젝트를 진행한 뉴미디어 팀은 컴퓨터공학과 학부생 4명으로 이루어진 팀으로, 긍정적 사회발전을 추구합니다.
분쟁이 아닌 분석을 통한 성장이 팀의 목적입니다. 이 페이지를 읽은 개인이 잠시 성평등에 대한 생각을 환기시키는 기회를 가질 수 있었길 바랍니다.
뉴미디어 팀의 프로젝트 과정 및 결과에 관심을 가지고 정독하여 주셔서 감사합니다.
수집 데이터
 2000년도 ~ 2019년도
'여성, 여자, 남성, 남자'가
포함된 기사
2000년도 ~ 2019년도
'여성, 여자, 남성, 남자'가
포함된 기사
 2005년도 ~ 2019년도
네이버
카테고리별 랭킹뉴스
2005년도 ~ 2019년도
네이버
카테고리별 랭킹뉴스
사용한 툴
데이터 분석 : pandas, numpy, torch, sklearn
데이터 수집 : beautifulsoup
협업 : github
시각화 : seaborn, matplotlib, pygal